22. Optimization Algorithm(梯度下降优化算法)¶
22.1. What to Optimize¶
Algorithms for optimizing gradient descent, because of the challenges
22.2. Evaluation the Algorithm¶
22.2.1. Convergence Speed¶
“Convergence Speed”可以定义为:经过多少次iterations,cost function达到最小值。一个拥有更快收敛速度的算法,在error surface的等高线图中的移动路径,可以从Momentum对SGD的改进中看出来。
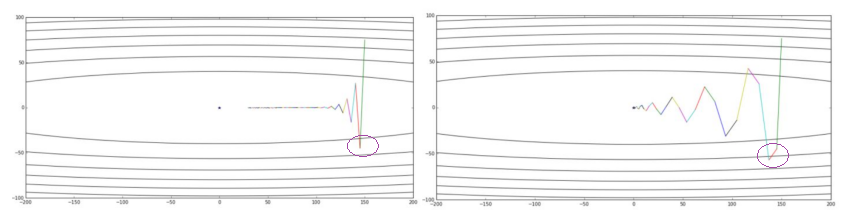
不同的优化算法比较speed时,可以比较在相同iterations数量下,哪个算法使cost function更加接近最小值,参见 SGD v.s. Momentum
提高某个算法的收敛速度——该快的时候快,该慢的时候慢,例如:
- move quickly in directions with small but consistent(一致性) gradients
- move slowly in directions with big but inconsistent gradients.
22.2.2. Convergent or Not¶
whether the learning goes wrong: convergent or not, global or local minimum
Plot J train (θ) as a function of the number of iterations of gradient descent.
- 坐标图中只需要一条曲线就可以判断
- 不同的learning method在曲线取样点的选择上有一些不同(From Andrew Ng Week 10)
22.2.3. Generalization¶
Generalization(Andrew Ng), underfit(high bias) or overfit(high variance)
在学习(迭代)的过程中,需要同时画两条曲线,通过对比才能判断。
22.2.4. Accuracy, Precision, Recall&F1 score¶
22.3. Concerns of an Algorithm¶
算法需要考虑的“因素”包括:
- learning method
- initialization of the weights
- the stride of the weight movment, 即learning rate
- direction of the weight movment, e.g. steepest descent的梯度反方向
- regularization, λ(Andrew Ng)
22.3.1. Learning method¶
对于神经网络而言,依据训练集的数据特点,有四种常用的学习方法:
22.3.1.1. full-batch method¶
适用于small datasets (e.g. 10,000 cases) or bigger datasets without much redundancy(冗余)
22.3.1.2. mini-batch method¶
(from Hilton)适用于big, redundant datasets, e.g. CNN中使用的图片数据。最好使用 big mini-batches ,不仅计算效率高、速度快,而且也满足一些fancy optimiaztion algorithm的需要。
还可以从 learning curve 的角度来理解mini-batch的可行性
mini-batch通常比online好,因为GPU上高效的矩阵运算。
相关概念:
- epoch
- iteration
- batch size
- number of batches
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch。
迭代是 batch 需要完成一个 epoch 的次数。记住:在一个 epoch 中,batch 数和迭代数是相等的。比如对于一个有 2000 个训练样本的数据集。将 2000 个样本分成大小为 500 的 batch,那么完成一个 epoch 需要 4 个 iteration。
22.3.1.3. stochastic method¶
22.3.1.4. online method¶
(From Andrew Ng 10th week)The online learning setting allows us to model problems where we have a continuous flood or a continuous stream of data coming in and we would like an algorithm to learn from that.
Online method的算法和stochastic method类似,但是,前者不保存training examples,用过之后即丢弃。
22.3.2. Size of the Step(Learning Rate)¶
22.3.2.1. How α influence the learning¶
根据Gradient discent的公式,
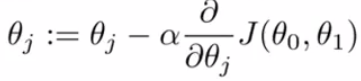
learning rate的取值大小通过直接影响Weights,进而影响cost function的收敛性,无法兼顾学习速度和收敛结果(是否成功找到cost function的最小值)。
- weights在 error surface 中的移动方式,会影响收敛速度和收敛结果
- learning rate太大,就湮没了不同weights分量的梯度的不同,因为是 learing-rate * gradient,进而导致收敛速度降低
22.3.2.2. When&How to adjust α¶
目前,有两种常用的调节learning rate的方法:
- 设置初值,根据learning speed再手工调节, e.g. SGD , Momentum, Nesterov Momentum
- 自适应, e.g. RMSProp, Adam, AdaGrad
22.3.2.3. Manual learning rate¶
| error |
|
|
|
| turn down α | reduce the random fluctuations(随机波动)in the error due to the different gradients on different mini-batch | slower | get a quick win |
| turn up α | weighs slosh to and fro(来回摇摆) across the ravine(峡谷),如下图 | quick | failed |
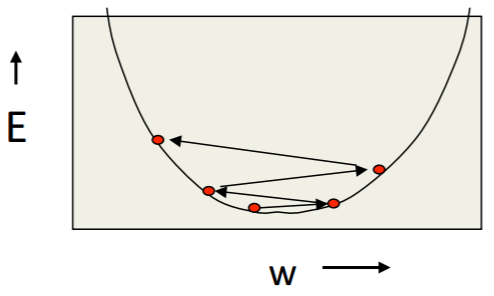
22.3.3. Descent Direction¶
22.3.3.1. Gradient Oscillation¶
- 在Hilton的课中多次提到gradient oscillation(振荡),我认为就是梯度的正负号的变化。
- gradient oscillation会改变descent direction,进而影响收敛速度。
- Gradient Oscillation可以在error surface的等高线图中可以清晰的表示出来, this 在对不同的learning rate的SGD之间,以及SGD和Momentum之间进行比较时,图示了Gradient Oscillation
- 梯度之所以为oscillation的原因,在上述链接的例子中,当y移动到负值时,根据梯度公式,cost function在这一点的梯度就取负值了。
22.3.3.2. The Direction of steepest descent¶
- network’s cost function下降的方向是由每个Δw决定的,可由等高线, Error Surface ,上w的移动看出来。
- cost function的值下降最快的方向就是梯度的反方向, but the direction of steepest descent does not point at the minimum unless the ellipse is a circle(from hinton lecture 6a)
- 有两种gradient(From Hilton)
- small but consistent(一致性) gradients
- big but inconsistent gradients.
(quickly和slowly是如何量化的呢?——learning rate)
22.3.3.3. Other directions of cost function descent¶
22.4. Instance¶
一个算法可能就出自一篇论文。
22.4.1. Summary¶
22.4.2. Momentum¶
- Momentum改进自SGD算法,计算公式的改变之处可以参见《Hilton lecture6》或者 An overview of gradient descent:Momentum , 这两者在求取v(t)时所使用的signs相反,应该无影响。
- 在求ΔW时,没有采用”steepest descent”(问题是,没有沿着梯度的方向,为什么还能加速?)
- Hilton says(lecture 6c) it can speed up mini-batch learning, 但是代价是引入了一个新的“动量衰减参数”
- 一个已经完成的梯度+步长的组合不会立刻消失,只是会以一定的形式衰减,剩下的能量将继续发挥余热。
- Momentum相比于SGD速度更快且振动减小了,体现在两个方面,如下图
- 从横轴看,The momentum term increases for dimensions whose gradients point in the same directions 。右图的紫色圆圈代表的一步迭代和左图对应的比起来,横轴上移动的更远。
- 从纵轴看,The momentum term reduces updates for dimensions whose gradients change directions. 右图的紫色圆圈代表的一步迭代在纵轴上几乎保持了和上一步相同的方向。
- 比较SGD和Momentum的weights的运动轨迹时,最大的区别就是“使得梯度下降的的时候转弯掉头的幅度不那么大了,于是就能够更加平稳、快速地冲向局部最小点”。
22.4.3. NAG¶
https://zhuanlan.zhihu.com/p/22810533
Nesterov Accelerated Gradient,简称NAG。它仅仅是在Momentum算法的基础上做了一点微小的工作,形式上发生了一点看似无关痛痒的改变,却能够显著地提高优化效果。
22.4.4. Rprop¶
- Hilton lecture6
- use a full-batch method
- use adaptive learning rates
引入了一个新的参数——local gain, g, α->α*g
22.4.5. Rmsprop¶
- Hilton lecture6
- use mini-batch method
- use adaptive learning rates