5. Dataflow Programming Model¶
5.1. What is programming model¶
Programming model,编程模型,是一种高层抽象;它独立于“编程语言”,用于扩充其”execution model”。例如,
- Mapreduce编程模型,用于大数据并行处理。
- POSIX thread library提供的API,让C语言程序也有了创建和操纵线程的能力(C语言的execution model不支持线程操作)。
5.2. What is Dataflow Programming¶
models a program as a directed graph of the data flowing between operations
5.3. Why dataflow graph¶
- parallel computing
- large-scale data processing
5.4. Four Concepts about Dataflow¶
Details of four major concepts on Google Cloud Platform
- Pipelines, 等同于tf中的subgraph
- PCollections, 等同于tf中的tensor
- Transforms, 等同于tf中的node
- I/O Sources and Sinks(input source and output sink),等同于tf中的inputing and outputing data
此四者的关系如下图所示,可见Dataflow就是由一个一个pipeline组成的:
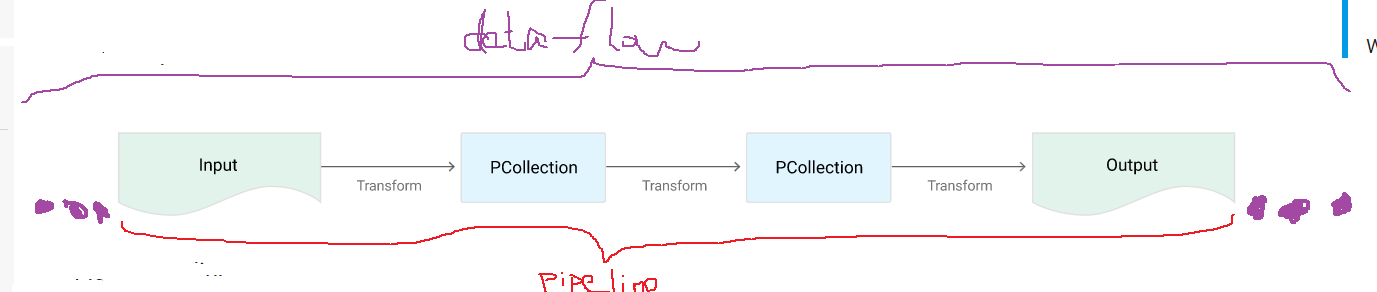
5.5. Look inside a pipeline¶
- composition
从上一小节看出,a pipeline等同于tf中的subgraph,有四个组件:input, transform, pcollections, output。Each pipeline represents a single, potentially repeatable job, from start to finish, in the Dataflow service.
- stages
pipeline的stages类似于tf中的collections,pipeline中的transforms are grouped into different stages and transforms of the same stage are executed in parallel.
- connections between stages
在用QueueRunner实现的tf “input pipeline”中,stages之间由queue来连接。
- direction
一个stage中的所有transform执行成功后,才执行下一个stage的transform
5.6. Pipeline Design Principles¶
对照上一小节“Four Concepts about Dataflow”,详见 Pipeline Design Principles on Google Cloudplatform, 请结合文中提及的四个基本问题来认识pipeline的五种形态。
5.7. Pipe and Queue in Python¶
有必要了解一些python实现pipe和queue的基本知识。在2016年实现的亚太主要英文媒体的舆情监控系统中其实已经用到了multiprocessing.Queue。
pipe和queue是“进程间通信”的两种方式,隐含了进程间的协作关系,“生产者”和“消费者”、“同步”和“互斥”的意义和实现,例如,queue满了后,发送进程会阻塞。所以应优先考虑Pipe和Queue,避免使用Lock/Event/Semaphore/Condition等同步方式 (因为它们占据的不是用户进程的资源)。
由package multiprocessing实现, on github, on docs
| pipe | queue | |
| 实现基础 | socket | pipe |
| 实现方式 | def Pipe() | class Queue |
| 容量 | 1 | maxsize |
| 传输方向 | duplex/single; send end&recv end | 无 |
| 关联进程数 | 一端只能一个进程 | 多进程读写 |
This link 中的“Pipe和Queue”部分有例程可以参考。
5.8. Threading and Queues in TF¶
5.8.1. Attention¶
In versions of TensorFlow before 1.2, we recommended using multi-threaded, queue-based input pipelines for performance. Beginning with TensorFlow 1.4, however, we recommend using the tf.data module instead. The tf.data module offers an easier-to-use interface for constructing efficient input pipelines. Furthermore, we’ve stopped developing the old multi-threaded, queue-based input pipelines.
5.8.2. What’s Queue¶
- TensorFlow’s queues are implemented using nodes in the computation graph.
- A queue is a stateful node, like a variable: other nodes can modify its content. So, there are nodes which can enqueue new items in to the queue, or dequeue existing items from the queue.
下图是a graph that takes an item off the queue, adds one to that item, and puts it back on the end of the queue.

说明:
- Enqueue, EnqueueMany, and Dequeue are special nodes which are created by calling methods on a queue object (e.g. q.enqueue(…)). They take a pointer to the queue instead of a normal value, allowing them to mutate its state.
- 无论通过什么其他的api来使用queue,都要用到上图中的几个node。
- Queue’s coordinator: a queue will block any step that attempts to dequeue from it when it is empty, or enqueue to it when it is full.
- TensorFlow implements several classes of queue. The principal difference between these classes is the order that items are removed from the queue.
5.9. Apache Beam¶
2016年2月谷歌高调宣布将Apache Beam(原名Google DataFlow)贡献给Apache基金会孵化,Apache Beam被认为是继MapReduce,GFS和BigQuery等之后,谷歌在大数据处理领域对开源社区的又一个非常大的贡献。