29. CNN¶
29.1. object recogonition遇到的困难¶
(来自hinton lecture5)从现实图片本身出发找,在object recognition遇到的困境(可能导致了识别精度不高):
- 如果直接把图片的每一个像素点作为一个input unit,”weight matrix” of “neural network with full connection”的维数太大,导致计算困难。
- 由viewpoint changes产生的”dimension hopping”,见下图。一侧的手写2由另一侧旋转(Rotate)和平移(Translate)而来,the dimensions that contain “2” are different which have been moved to other dimensions. 手写时,这种情况很普遍,并且training set 不可能穷尽所有的”viewpoint changes”。如果用左侧的图片来训练,是否可以识别出右侧的图片?

- Deformation。a hand-written 2 can have a large loop or just a cusp(尖头),这两种情况都属于2的“手写形变”。每个人的字迹不一样,这也是普遍现象,但是training set不可能穷尽所有形变。用前者作为训练数据,神经网络可否识别出后者?
29.2. 为什么用CNN进行对象识别以及CNN带来的好处¶
用CNN进行对象识别原因更多从对象本身的特点以及识别难点出发,然而,CNN带来的好处更多从计算的便利性出发,两者相互区别又相互联系的议题。
29.2.1. CNN的神经科学解释¶
下面的科学解释是设计CNN的”prior knowledge”(先验知识)
- 1959年,Hubel和Wiesel的实验表明生物的视觉处理是从简单的形状开始的,比如边缘,直线,曲线,并凭借这一发现获得了诺贝尔奖。——CNN有多层卷积层,后面的层都会抽象组合成更高阶(全局些)的特征,保留了图像的空间信息,保持特征的空间不变性。
- 19世纪60年代,科学家通过对猫的视觉皮层细胞研究发现,每一个视觉神经元只会处理一小块区域的视觉图像,即感受野(Receptive Field)。——卷积神经网络的概念即出自于此。
- 图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。
29.2.2. Why CNN¶
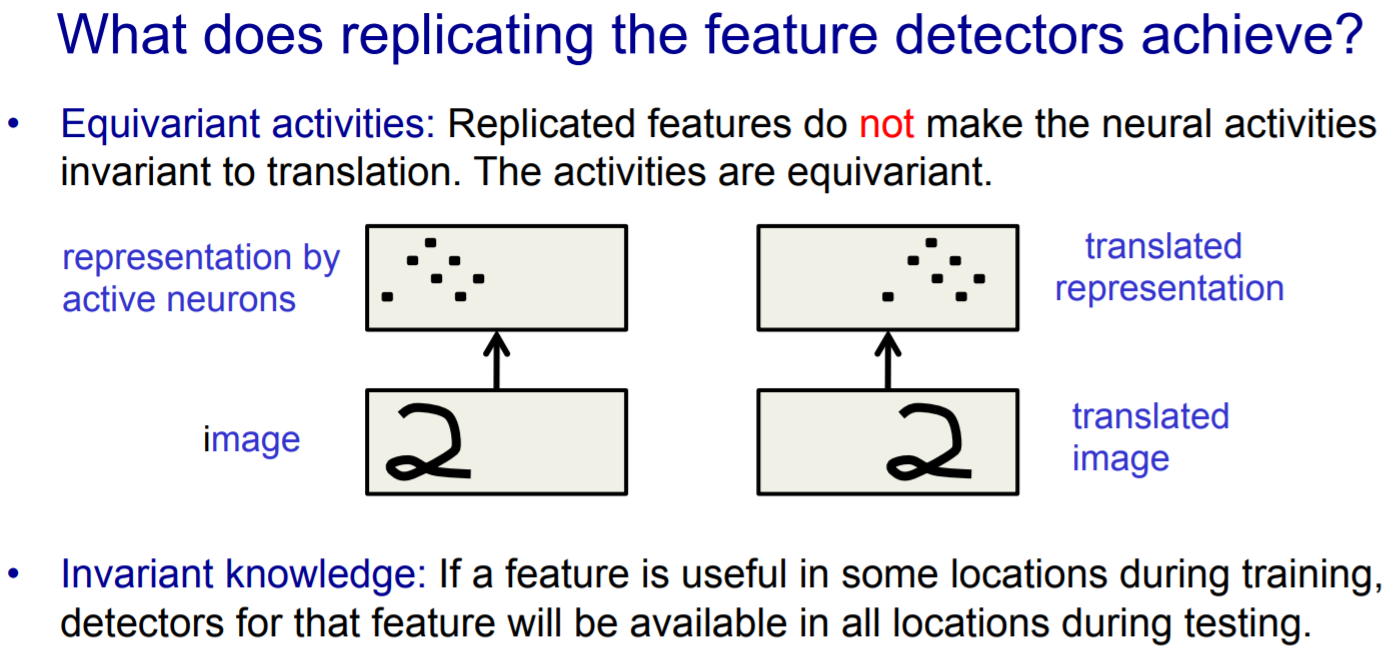
- replicated feature approach针对上述的“困难2”。下图中,active neurons实现了和image translation(平移)的同变。那么,这种同变性是对训练好,还是对识别好?
29.2.3. CNN的好处¶
- 避免了对图像的复杂前期预处理,可以直接输入原始图像。
- 局部连接(Local Connection)和权值共享(Weight Sharing)减少了计算量
29.3. 术语解释¶
- 卷积核
- 又可称为”feature detector”.
- shape is [filter_height, filter_width, in_channel, out_channel],
- feature map:每个卷积核生成的另一幅图像
- 通道:包括
- in_channel, 卷积前的图像,例如,RGB就是3通道, ARGB就是4通道;或者是上一卷积层中卷积核的数量
- out_channels, out_channels==本卷积层的kernel_numbers
- replicated feature approach
- 定义:use many diffrent copies of the same feature detector with different positions.
- CNN中的“C”,应该是代表了replicated feature approach。把图像的多维数据摊开到一维,移动卷积核,与图像数据相乘求和,这种计算过程,和两个离散信号求卷积的过程相同。
- Training data
- shape is [batch-size, channels, height, width].
29.4. Graph(网络结构)¶
典型的CNN由如下三个部分级联而成:
- 卷积层(卷积+池化)
在进入“全连接层”之前,找出合适的features数以代表原始图片作为“全连接层”的输入。虽然降维了,但是也不能太少,否则无法代表原始图片。
- 全连接层,得到固定长度的特征向量
- softmax,进行分类
29.4.1. 定义Graph的流程¶
- 用tf.placeholder()定义整个CNN 4-D input of shape [batch, in_height, in_width, in_channels]
- 用tf.Variable()定义卷积层使用的 4-D weight of shape [filter_height, filter_width, in_channels, out_channels] and 1-D bias of shape [out_channels]
- 定义单卷积层的组件: conv operation, pool operation…
- 用单层(第1层)的参数,包括卷积核的尺寸和个数,还有卷积和池化的步长等初始化weight、bias和conv/pool operation,把input等连起来,定义单层卷积层
- 把上一层的output作为input,重复上一步,定义下一层卷积
- 定义全连接层、Dropout层和Softmax层
29.5. 卷积层¶
每个卷积层要完成两个操作:
- 抽取特征
- 抗形变(deformation)
29.5.1. How to 抽取特征¶
- 一个卷积核的输出的意义是,一副图在不同位置的相同特征(replicated feature approach)
- 一副图在相同位置的不同特征,分散在不同卷积核输出的相同位置。
29.5.2. How to 抗形变¶
形变:a hand-written 2 can have a large loop or just a cusp(尖头),这两种情况都属于2的“手写形变”
- 激活函数
激活函数本身就是 neuron model 的一部分,不是从属于CNN或者是RNN。
- 池化
池化简单来说就是将输入图像切块,大部分时候我们选择不重叠的区域,再取切分区域中所有值的均值或最大值作为代表该区域的新值,放入池化后的二维信息图中。
池化操作和卷积操作很类似,都存在kernel_size和stride两个重要参数,池化可以理解为卷积核都为1的卷积。
29.5.3. 池化的作用¶
- 抗形变
e.g. a hand-written 2 can have a large loop or just a cusp(尖头),这两种情况都属于2的“手写形变”
- 降维
图像经过多核卷积后,dimension往往会增加,见hinton, Lecture 5a, LeNet5。pooling会减少下一层”feature extraction”的输入数量,所以,在下一个”feature extraction layer”能有更多不同的”feature mpas”,例如,在MTCNN和LeNet5的网络结构图中,后面的卷积层往往拥有比前面的更多的卷积核。
- (副作用)丢失物体的精准位置信息,在一些识别场景——需要用到”precise spatial relationship between high-level parts”中,就有问题。例如,识别眼睛和鼻子
- 池化的尺寸和步长不一致,可以增加数据的丰富性,一般,尺寸>步长
29.5.4. 多层结构的意义¶
较浅的卷积层(靠前的)的感受域比较小,学习感知细节部分的能力强,较深的隐藏层 (靠后的)感受域相对较大,适合学习较为整体的、相对更宏观一些的特征。
29.6. 卷积运算时参数的个数¶
在创建卷积核所对应的参数矩阵时,每一个卷积层的参数矩阵的shape是[filter_height, filter_width, in_channel, out_channel]。我自己产生了一个疑问——in_channel这个参数是否必须?换言之,一个”filter kernel”在不同channel上进行卷积运算时的参数是否相同,如果相同,in_channel仅仅就是为了计算方便,在不同的in_channel扩展相同的filter_height*filter_width?
答案是——一个”filter kernel”在不同channel上进行卷积运算时的参数不同,换言之,in_channel这个参数是必须的并且是有现实意义的。
每一层卷积层需要的参数个数的公式是:
1 | out_channel * (filter_height * filter_width * in_channel) + out_channel
|
上述公式中:
- (filter_height * filter_width * in_channel)是一个卷积核的参数矩阵
- 最后”+ out_channel”的意义是bias
例如,AlexNet中第1层卷积的参数达到了35k,见《tf实战》p99