24. Generalization(泛化)¶
24.1. Regularization(正规化)¶
24.1.1. L1 Regularization¶
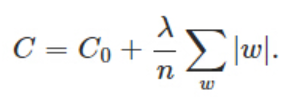
24.1.2. L2 Regularization¶
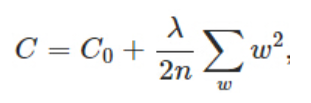
从《tf实战》5.3的例子看出,在一个神经网络中,
- 并非要对每一层的weights进行penalization。书中的例子,只对整个神经网络中间的全连接层进行了regularization(p89),而对于前面的卷积层(p88)、后面的softmax都没有进行这个操作。
- bias不参与regularization
24.1.3. Dropout¶
24.1.3.1. Dropout概念的出处¶
Dropout来自于论文 Improving neural networks by preventing co-adaptation of feature detectors, 作者是鼎鼎有名的Hinton。虽然论文链接中指给出了summary,但是依然信息量巨大:
- 手段就是“ randomly omit half of the feature detectors on each training case. ”
- 关于co-adaptation,论文摘要中给出了2个关键表达:“context of several other specific feature detectors” v.s. ” internal contexts”
- 应用场景: a large feedforward neural network+ trained on a small training set
更加深入地理解,可以看看Hinton和Alex两牛2012的论文《ImageNet Classification with Deep Convolutional Neural Networks》
24.1.3.2. droput原理¶
正则化方法 中的“Dropout”部分,要注意:
- 使用mini-batch learning method时,在mini-batch中的每一个training case,隐去的神经元必须是一样的。因为按照BP的原理,把一个mini-batch中的所有training case运算一个来回(FP+BP),weights才会迭代一次,但是,隐去的神经元的weights不更新。
24.1.3.3. Usage¶
- AlexNet“首次”在最后的几个“全连接层”使用了Dropout,以随机忽略一部分neurons。注意,并非在“卷积层”使用dropout。见《tensorflow实战》p98(2)的描述,但是书中没有给出代码。
- 示例代码见《tensorflow实战》p82,Dropout层用在了全连接层的后面,softmax之前。
- tensor经过dropout后的变化可以参见 谈谈Tensorflow的dropout
24.2. Data Augmentation¶
“数据增强”可以增多training set,也是防止overfit的常用方法。用CNN进行图像识别时,其意义见《tf实战》p93
this article 中的“数据集扩增”部分讲的很好,还有相关论文,暂时没有时间看。
the article 详述了对MTCNN中所使用的”data set”进行data augmentation的过程
24.3. LRN¶
LRN,局部响应归一化,AlexNet首次引入。用在神经网络结构中的哪里呢?
作用:对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的neuron,增强了模型的泛化能力。