23. Bias v.s. Variance¶
用J train (Θ)的绝对值衡量bias, 用J train (Θ)和J cv (Θ)的相对值衡量variance。
23.1. Definition¶
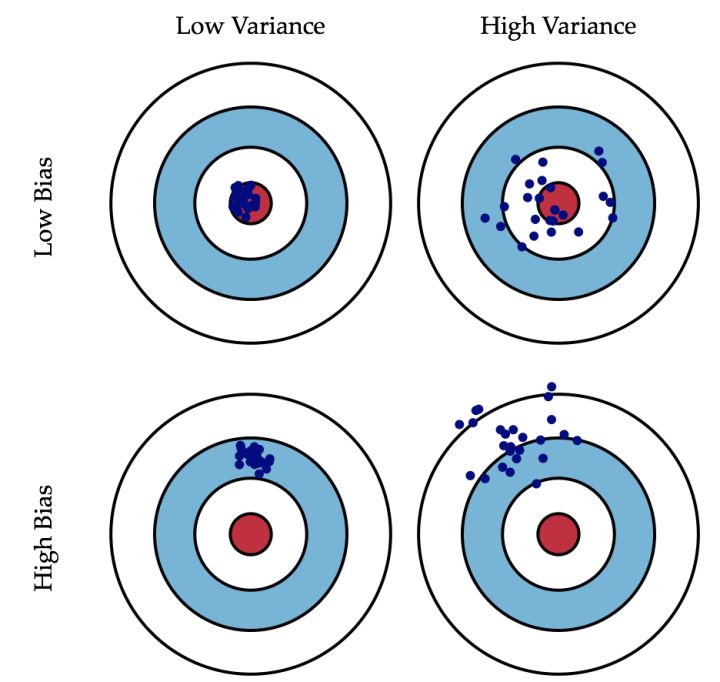
偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如下图第二行所示。
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如下图右列所示。
23.2. Overfitting and Underfitting¶
- Over fitting occurs when the model captures the noise(噪音) and the outliers(离群值) in the data along with the underlying pattern. These models usually have high variance and low bias. These models are usually complex like Decision Trees, SVM or Neural Networks which are prone to over fitting.
- Under fitting occurs when the model is unable to capture the underlying pattern of the data. These models usually have a low variance and a high bias. These models are usually simple which are unable to capture the complex patterns in the data like Linear and Logistic Regressions.
23.3. High Bias or High Virance¶
23.3.1. 方法1¶
第1步,learn parameter θ from training set
对于回归问题,使用的learning target如下图所示
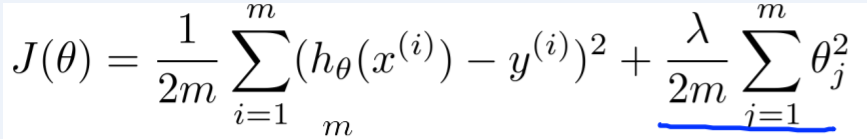
第2步,待模型训练结束后,compute J train (Θ) from training set and J cv (Θ) from cross validation set
- 对于回归问题, 公式如下图,注意,其中没有”L2 Regularization”
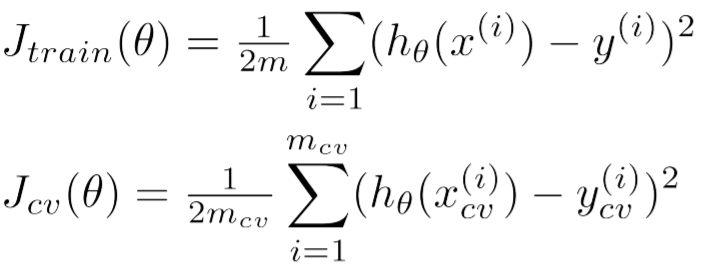
- 对于分类问题,J train (Θ)和J cv (Θ)既可以用“互熵”,也可以用”Misclassification error”来计算,例如下图的“二分类”计算公式:

第3步,比较J train (Θ)和J cv (Θ)的值to select the model
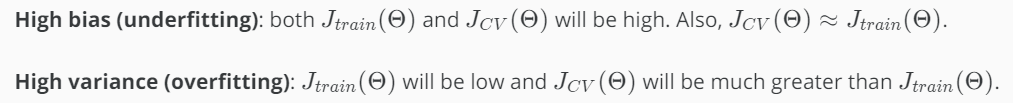
针对high bias或者high variance来调整模型。但是,要注意的是,调整的点不同,J train (Θ)和J cv (Θ)的变化趋势也不同。
- 调整模型复杂度
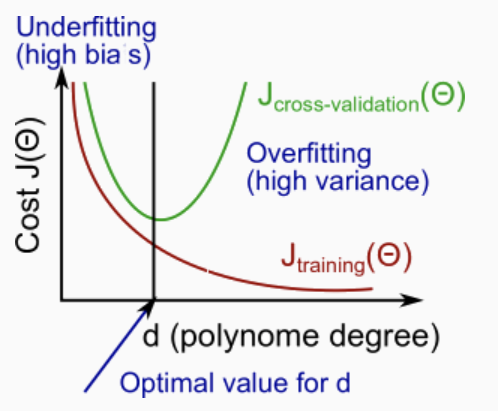
- 调整regularization parameter
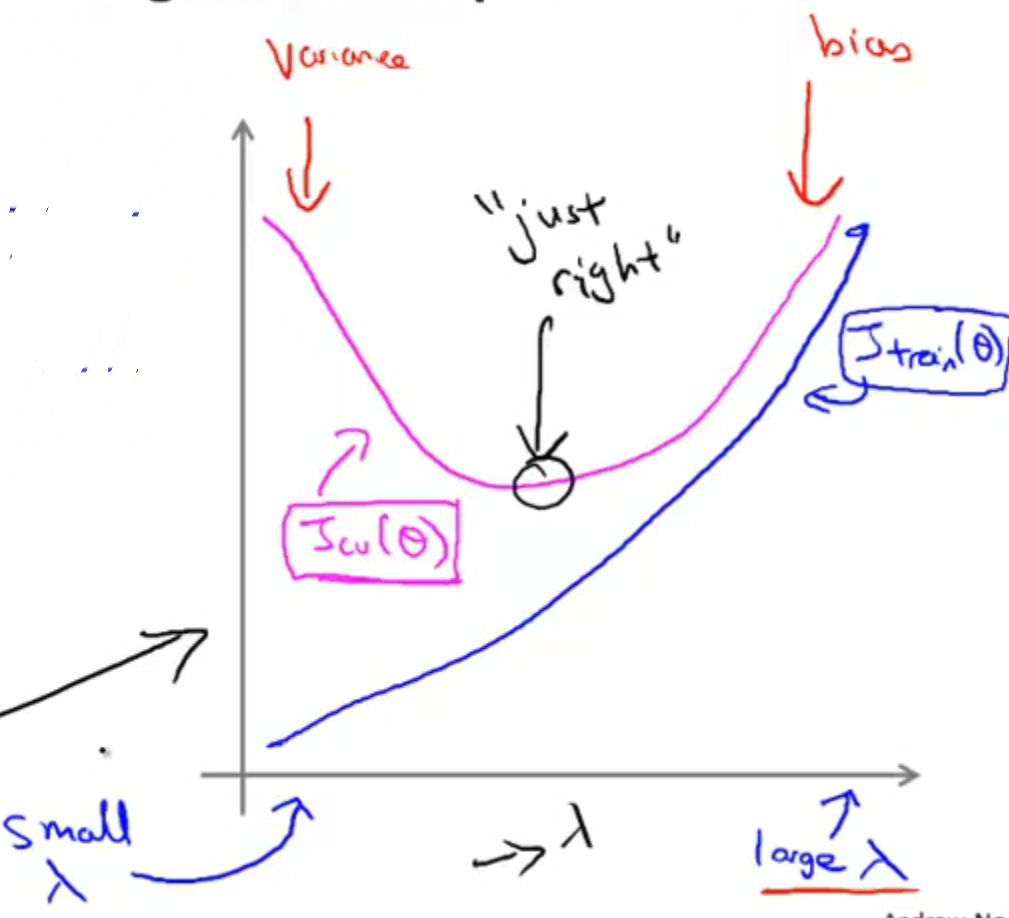
第4步,estimate generalization error for test set using J test (Θ)
23.3.2. 方法2 Learning Curve¶
STEP 1, 确定好model and learning target(cost function)
STEP 2, 从”training set”中选出“数据量逐步增长的子集(training subset)”,针对每个”training subset”, 完成3小步,
- minimize the learning target to learn parameter θ on the training subset
- 计算J train (Θ) on the training subset
- 计算J cv (Θ) on the validation set
STEP3, 画图判断high bias or high variance

