27. Neural Network¶
27.1. 大脑神经网络的结构¶
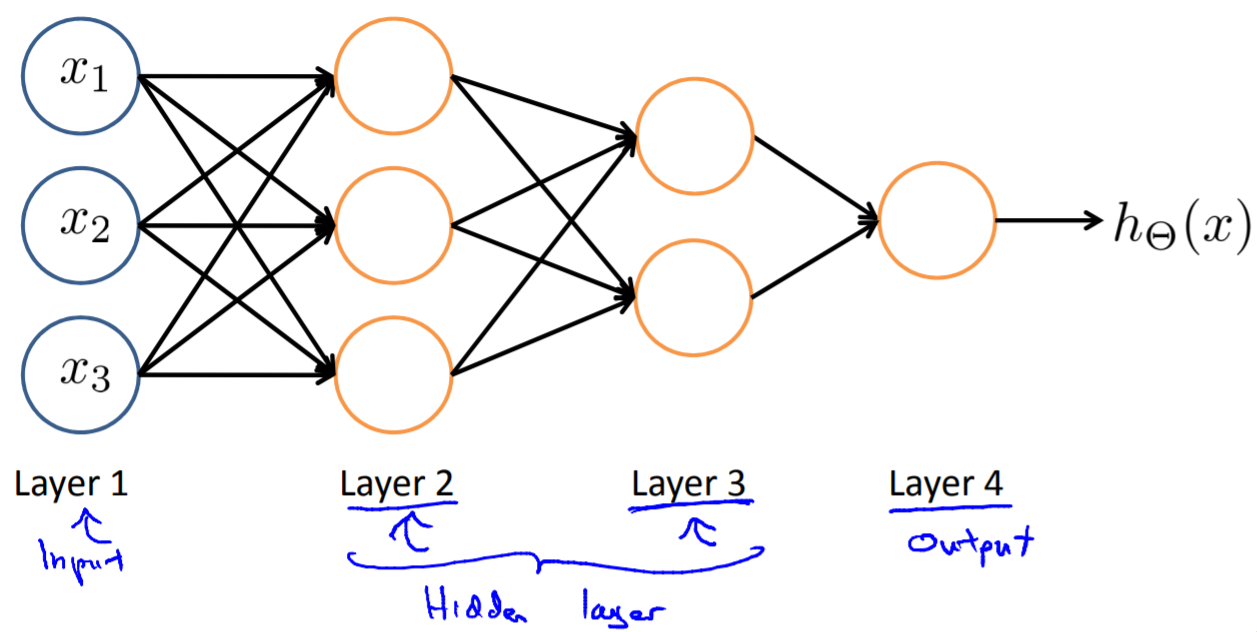

27.3. Three Network Architectures¶
from hilton week2
这三种网络结构和三种学习方式是否有对应关系?
27.3.1. 网络结构设计¶
- 一般默认,1 hidden layer, or >1 hidden layer, have same no. of hidden units in every layer(usually the more the better)
27.4. Backpropagation Algorithm¶
这一小节的内容摘自Andrew Ng Week5 p24b-24c, p34-36
27.4.1. 神经网络求解weight matrix面临的问题¶
对于神经网络(hidden layer>=1)而言,求得整个网络的loss对每一层的每一个 θ ij 的偏导数,就无法用与在机器学习中所用到的相同的方法求得了。BP算法就是为求这个偏导数而生的。
27.4.2. BP算法的思想¶
- forward propagation求得last layer的”error values”;
- (这一步体现了BP的精髓)由last layer的”error values”进行backpropagation,求得L-1, L-2,…2层的”error values”;
- 由layer j的”error values”求得layer j-1 to layer j的 accumulated gradients,Δ, j=2,…L
- 对每一个training data计算1-3步
- 由Δ求得梯度。

27.4.4. weight matrix initialization¶
详见 Andrew Ng week5 p30
- 初值的取值范围
- dimension of weight matrix from layer j to layer j+1
- weight matrix的计算公式
27.4.5. BP算法的弱点¶
- 梯度弥散(vanishing gradient problem)
当使用反向传播方法计算导数的时候,随着网络的深度的增加,反向传播的梯度(从输出层到网络的最初几层)的幅度值会急剧地减小。结果就造成了整体的损失函数相对于最初几层的权重的导数非常小。这样,当使用梯度下降法的时候,最初几层的权重变化非常缓慢,以至于它们不能够从样本中进行有效的学习。
例如,在AlexNet中,使用ReLU neuron替代了sigmoid neuron,成功解决了Sigmoid在网络较深时的梯度弥撒问题。
27.5. Construct a NN in TF¶
27.6. 使用NN的一般流程¶
- 准备数据
- 设计网络结构(Graph Level in TF)
- 根据training data set, 设计网络的 input layer 和 output layer
- 根据应用场景设计 hidden layer , e.g. How To Define CNN Graph
- 定义cost function
- cost function往往由整个CNN中最后一层的形态和意义来决定
- 最好加入 penalty factor——λ,以免过拟合
- 定义使cost function最小化的优化算法
需要设置一个参数learning rate,用于余梯度下降时控制下降的速率。
- 定义评估操作
- Train Model
- 迭代地对数据进行训练
- 在全部训练完成之后,在最终的测试集上进行全面的测试
27.7. 应用场景¶
用神经网络可以解决
- 分类问题
- 回归问题
27.7.1. 图像语义分割¶
图像的语义分割是像素级别的分类问题
《语义分割中的深度学习方法全解:从FCN、SegNet到各代DeepLab》 https://zhuanlan.zhihu.com/p/27794982
《十分钟看懂图像语义分割技术》 https://www.leiphone.com/news/201705/YbRHBVIjhqVBP0X5.html